About
In Franco Moretti’s (2005) Graphs, Maps, and Trees, he traced trees as visualizations back to Darwin’s evolutionary tree in The Origin of Species and also to genetic trees that show the branching of languages from shared roots. Such trees, drawn painstakingly by hand, allowed the viewer to visualize a great deal of information about the relationships among various animal species or among language variants. Family trees serve similar functions for tracing relationships among people; these sorts of trees are compact and efficient ways to express previously identified relationships.
Word trees, on the other hand, were developed for the purpose of revealing unanticipated or unseen relationships among words in texts or corpora. As Verena Lyding and Michel Genereux (2016) pointed out, word trees serve corpus and linguistic analyses by providing a data overview in compact form. Because font size corresponds to word frequency in word trees, the most relevant data can be identified, and the interactive features of trees allow for preliminary exploration of the data. Martin Wattenberg and Fernanda Viégas (2008) noted that word trees build upon keyword-in-context (KWIC) corpus analysis techniques, making them more interactive by using the visual design to highlight repetitions and to facilitate exploration of the word’s context. Wattenberg and Viegas’s Word Tree first appeared on Many Eyes, IBM’s online visualization site, and allowed users to explore texts of up to one million tokens. Word Tree did not identify a “starting point” for users; rather, users chose a term they wanted to explore. In this sense, they are corpus-based, rather than corpus-driven, visualizations (Mackiewicz & Thompson, 2016).
Following Wattenberg and Viegas, Chris Culy and Verena Lyding (2010) developed DoubleTree, which was intended to correct a number of problems with Word Tree as a visualization tool for KWIC and to make it more useful for linguists. Chris Culy’s (2014) version, in particular, replicated the “two-sidedness” of a conventional KWIC table, showing the context both preceding and following the keyword, thus the designation “DoubleTree.” In contrast to Word Tree, which is always fully expanded and shows branches until they define a unique phrase, DoubleTree shows just one word of context on each side. Each word can be expanded by clicking to show the development of single paths; the expansion of a new keyword hides the expansion of a previous keyword. DoubleTree also solves the problem of identifying corresponding preceding and following contexts; it shows word frequency and the branching factor (the number of preceding or succeeding continuations of the word) and it does so without hiding information, as Word Tree does. DoubleTreeJS (Culy, 2014) is a JavaScript reimplementation of DoubleTree and includes some improvements, including the ability to sort branches and to search words in the tree. DoubleTreeJS can also work with structured data. It is on DoubleTreeJS that the Voyant WordTree tool is based.
When the WordTree tool is chosen in Voyant, it provides, by default, both preceding and following contexts for the most common word in the corpus. The researcher can also create a WordTree on a focus word by typing the word into the search box. Using the “limit” slider, it is possible to expand and contract the number of concordance terms retrieved (from 10 to 1,000); the “branches” slider allows the user to determine the number of branches displayed on each side of the keyword (from 2 to 15); and the “context” slider controls the length of the context provided (from 3 to 20 words). The user can also determine stop words. Clicking on branch terms reveals preceding and following contexts for the terms.
In Voyant WordTree, the tree limits the number of “concordances” (preceding and following contexts) for each word; the contexts that appear are not necessarily based on frequency. Moreover, the limitations of the display make it difficult to view large trees at one time. Mousing over any term in the tree displays information about the token in the tree: the “count” (number of occurrences); the id; and the number of “continuations.”
Examples
Voyant WordTree is most useful for exploring keywords in context because it offers a visual and interactive interface. Indeed, Wattenberg and Viégas (2008) called it “an interactive form of the keyword-in-context (KWIC) technique” (p. 3). By selecting keywords (identified from Voyant’s Document Terms tool), the researcher is able to explore visually how those words are used in their contexts within the corpus. The two tools are linked: selecting a term from the Document Terms tool with the WordTree tool open causes a WordTree visualization to appear for the term.
To do our WordTree analysis, we first identified keywords using Voyant’s Document Terms tool (see the Tables section of this webtext). After eliminating some common stopwords, “grammar” appears as the second most frequent term in the list of Document Terms from the combined institutional data, though its relative frequency is much higher in the Michigan State University corpus than it is in the University of Michigan corpus. Because of its prominence in the combined data—and because of the differences in its frequency in individual corpora—“grammar” seemed worth exploring. In addition, the evolving conversation within writing center studies about how to address sentence-level or “lower-order” concerns to address needs of students often marginalized in educational settings (see, for example, Denny, Nordlof, & Salem, 2018; Grimm, 2011; Myers, 2003) gestures towards the importance of looking at this word more closely.
The WordTree visualization allows researchers to explore consultants’ use of the word “grammar” in its context and to test hypotheses about “grammar.” This exploration allows us to address questions like: How are consultants talking about grammar in the context of their session notes? And how does this “conversation” about grammar in the writing center fit into broader disciplinary conversations about standard English? Could a corpus-based analysis of consultants’ use of “grammar” in their session notes shed some light?
Figure 17. An embedded interactive Voyant WordTree for the word “grammar,” using the sample corpus. Words such as "his" and "for" appear as branches.
The word “grammar” occurs 8,929 times in the combined corpus; of these 8,929 occurrences, 20 are represented in the WordTree visualization (Figure 18). So that full WordTrees could be represented in this webtext, we limited the number of concordance entries retrieved to 40. The number of branches, however, is maxed out at 15, and the number of contexts to 20. It should be noted that the Voyant Contexts tool—another KWIC tool—also permits the user to see each occurrence of “grammar” in its context; however, these occurrences are presented in the order in which they occur in the text. WordTree permits the visualization of connections between the root word and its contexts and provides ways to interact with the text that allows us to understand consultants’ use of the word “grammar” in a more complex way.
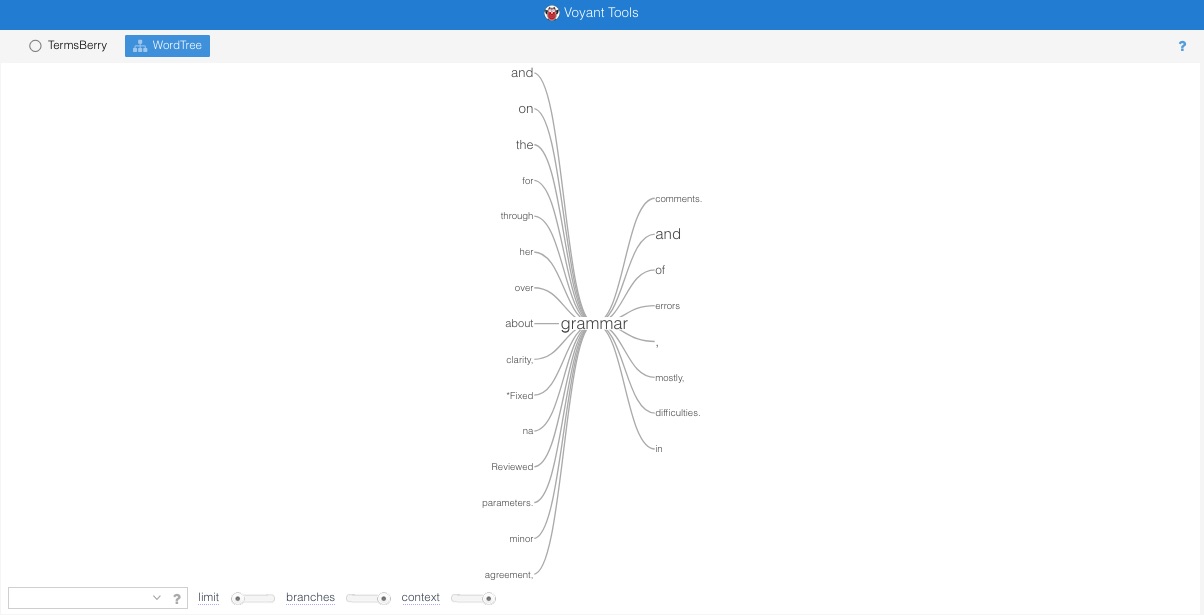
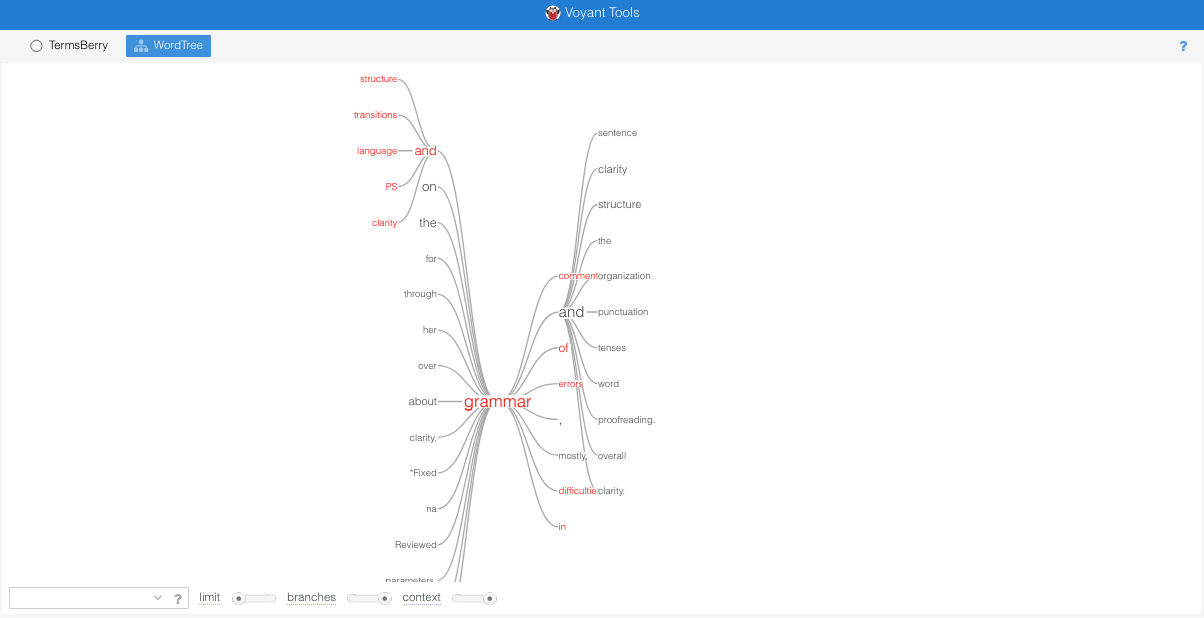
Looking at Figure 18, we can see that the biggest branches are displayed in larger text size. “And” (word count: 6) and “on” (word count: 5) are the most frequent preceding branches for “grammar.” “And” (word count: 13) is the most frequent continuation. The prominent appearance of “and” in both preceding and continuing branches suggests that grammar is almost always connected by consultants and writers with other concerns. The expansion of “and” in both directions in Figure 19 demonstrates what some of these concerns are; some are closely related to grammar, such as “language,” “clarity,” “punctuation,” and “proofreading,” while others are more distinct from sentence-level concerns, including “structure,” “organization,” and “transitions.” Moreover, while both “on” and “and” preceding “grammar” have multiple preceding branches (four and five continuations respectively), most other words that precede “grammar” have only one continuation. When it follows “grammar,” “and” has 11 continuations, further reinforcing the connection between grammar and other writing concerns, large or small. This brief closer look at our consultants’ use of the word “grammar” in their session notes suggests that consultants take seriously the importance of balancing higher-order and lower-order concerns in their consultations; “grammar” rarely stands alone in a session note but is instead often paired with other terms that represent other writing issues.
Implications
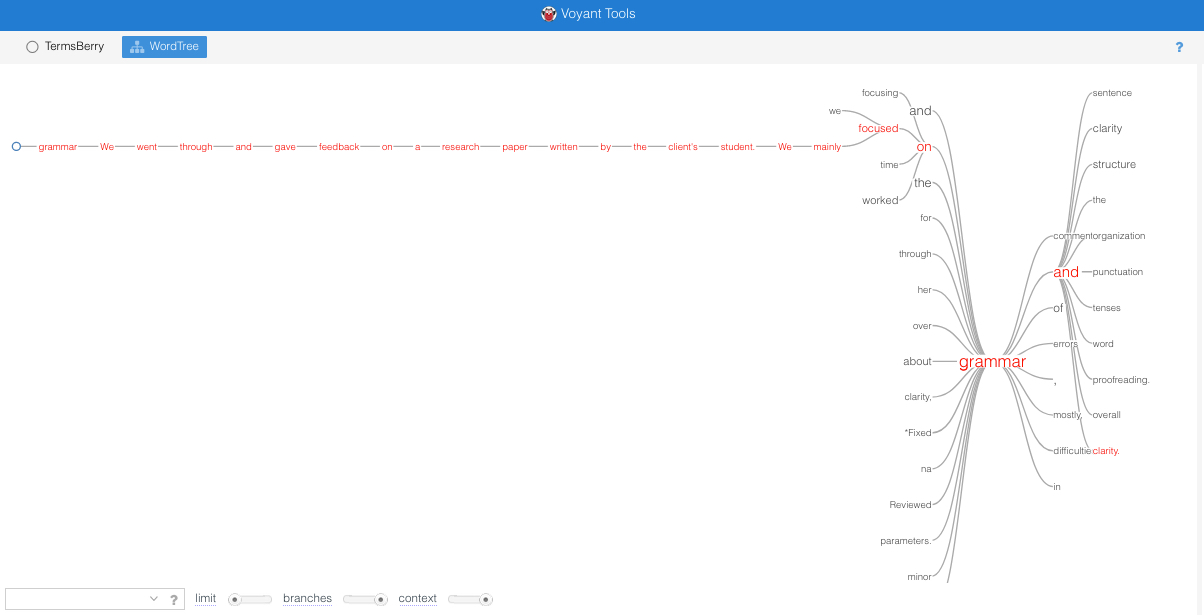
The Voyant WordTree tool allows for dynamic interaction with unstructured text in ways that allow the user to explore the most frequent connections between words in a corpus. By examining the branches that precede and follow the most frequent word in the corpus or a user-selected keyword, such as “grammar,” one can see whether the use of that word is confined to a rather narrow set of contexts or whether the contexts are expansive. For instance, even when fully expanded, “grammar” has many preceding branches, but fewer following branches.
As Andres Esteban and Roberto Theron (2011) pointed out regarding another word tree visualization tool, CorpusExplorer, 2- and 3-grams (contiguous sequences of two and three words) are visualized by the WordTree, thus providing insight into frequently occurring sets of words in the corpus, as well as the broader contexts for those words. In this way, word trees permit not only the analysis of text, but also its synthesis (Sinclair & Rockwell, 2012). Digital visualizations, such as Voyant’s WordTree, allow us to break the text apart and put it back together in new ways, revealing aspects of the text not available to us without such tools. Experimentation with various parameters of the tools and interactions among the various tools (in this case, Document Terms and WordTree) allow different aspects of the text to be revealed (Sinclair & Rockwell, 2016). However, these tools depend upon “a wide range of human choices, from the encoding of the digital text and the programming of the analytic tool to the parameters selected by the user and the way results are read” (Sinclair & Rockwell, 2016, p. 285). Therefore, we must remain aware that the tools themselves are limited: “they count, compare, track and represent words, but they do not produce meaning—we do” (Sinclair & Rockwell, 2016, p. 288). For writing center researchers wanting to better understand consultants’ language use and the thinking it represents, WordTree visualizations offer opportunities to explore keywords in context and understand how certain formulations repeat themselves, making some meanings possible and others impossible, throughout a corpus of writing center texts.