![Screenshot of Hypnotoad from the Episode 'Bender's Big Score' on Netflix with caption: [droning mechanical sputtering]](assets/hypnotoad-bendersbigscore-netflix.jpg)
Captioning Hypnotoad—A Quest That Helped Define a Field: An Interview with Sean Zdenek
Modeling Research
For new and emerging fields like caption studies, it is important for researchers to have models or examples to follow. Sean Zdenek clearly employs close analysis and multiple rhetorical approaches in his work. Fortunately, the interdisciplinary nature of caption studies allows for an array of different research methods, methodologies, and approaches. As one of the early researchers in caption studies, at least with a humanities emphasis, Zdenek is also modeling research and research methods for future researchers. These questions were meant to help understand how Zdenek sees caption research and how he models and teaches caption research or captioning in his courses.
[gz] Have you taught captioning research methods in any of your classes? Or have you focused mostly on how to caption?
[SZ] I've focused mostly on showing students how to caption. But these how-to sessions can raise compelling questions for students that go beyond the simple mechanics of how to use a software program. Captioning seems like an easy task for students until they actually settle in and try to do it, such as selecting which sounds to caption in a dense sonic environment, identifying speakers and accents, understanding audience needs, and rhetorically inventing appropriate words to describe significant nonspeech sounds. Topics they may have never considered before now take on greater importance, such as breaking caption lines for sense, adhering to reading speed guidelines, and distinguishing two or more speakers in the same scene.
In my web accessibility and disability studies course, we usually spend multiple class sessions talking about captioning and learning captioning software. To demonstrate Amara.org, a do-it-yourself online captioning program, I selected an official video produced by one of the departments at my own institution. As you know, many departments on college campuses create promotional videos intended for public consumption, posting them on their web pages and sometimes on YouTube. At my own institution, so many of these public-facing, officially sanctioned videos are uncaptioned, which is an important lesson for students in terms of the value and awareness (or lack thereof) placed on accessibility and the law. For my fall 2015 class, I selected a slick video produced by the athletics program at my institution to promote our 2015 college football team. In lieu of professional captions, the original "Fearless" video (Texas Tech Red Raiders, 2015) was (and still is) auto-captioned. The resulting captions are full of speech recognition errors, providing students with another important lesson about the value of human editors in the captioning process. Recently, I captioned the video myself using Amara:
Note: Use the Amara CC toggle switch to view Zdenek's captions. You can also turn on both Amara and YouTube captions and compare versions.
What was initially intended to be a how-to session on using Amara turned into a rich discussion about speaker identifiers and the ethics of potentially giving caption readers more information than listeners. This promotional video uses pounding instrumental music and audio clips from a number of well-known sports sources. Indeed, the only speech in the video comes from these external sports sources as images from the football program are spliced together in quick succession:
- Al Pacino as fictional coach Tony D'Amato in Any Given Sunday (Stone, 1999): "…we can fight our way back into the light. We can climb outta hell… one inch at a time." And at the end of the video: "Inch by inch, play by play. Until we're finished."
- Coach Vince Lombardi's pregame speech to his players in Super Bowl II (1968; Kramer, 2010): "Just hit, just run, just block, and just tackle. You do that and there's no question what the answer is going to be in this ball game. Keep your poise. There’s nothing that they can show you out there you haven’t faced a number of times. Right?" Players respond: "Right!"
- Sylvester Stallone as Rocky Balboa in Rocky Balboa (Stallone, 2006): "But it ain't about how hard you hit. It's about how hard you can get hit and keep moving forward; how much you can take and keep moving forward. That's how winning is done! Now, if you know what you're worth, then go out and get what you're worth. But you gotta be willing to take the hits, and not pointing fingers saying you ain't where you wanna be because of him, or her, or anybody. Cowards do that and that ain't you. You're better than that!"
- Kurt Russell as Coach Herb Brooks in Miracle (O'Connor, 2004): "This is your time. Now go out there and take it."
When an actor is playing a character in a movie but none are named in the audio track—even if all three are well-known to some audiences (Pacino, D'Amato, Any Given Sunday)—how should the captioner proceed without filling up the allotted caption space very quickly? Style guidelines tend to focus on off-screen speakers and unnamed narrators but this video suggests that some situations can be much more complex.
To my students, this video laid bare the simplicity of naming guidelines in the face of multiple layers of names. My students also wondered about the implications of providing information on the caption track about names, characters, and movie titles that weren't originally known to some viewers. For example, a listener who may have recognized Pacino's distinctive voice may not have also known that he was giving a speech as a character in a sports movie. Questions about cultural literacy become relevant. How do captioners recognize that a line of speech is actually from a well-known source in the first place? What counts as well-known? How do captioners find and verify that source if they suspect one but don't have any evidence for it in the official script/documents received from the producers? Once we've verified the source, how do we transcribe it so that we maintain the flavor of the original (e.g., represent informal speech forms and significant accents when present)?
These questions can offer jumping off points for discussions of research methods in captioning. What became clear to my students was that captioning itself is a form of research that involves sizing up the situation and the audience's needs, applying literate knowledge to recognize and understand sonic allusions, and negotiating the constraints of time and space on the caption layer. From here, we can move to questions that they, as new captioning researchers, might want to study. For example, our sports video raises larger questions about the limits of style guidelines, the roles of names and naming conventions, methods of doing audience analysis, the scope of cultural literacy, genre expectations and differences, and so on. These questions can serve as incipient research topics for students and others interested in caption studies.
Scholars in the humanities have only recently set out to create a more complete roadmap for making sense of the rhetorical landscape of closed captioning. In my research, I have drawn on and created a number of methods and tools for
- transferring clips from TV–DVR to PC;
- extracting caption files from DVDs;
- creating and searching a corpus of caption files;
- using software tools to analyze captions, from spreadsheet programs to concordancers;
- using software tools to visualize captions as timelines, graphs, word clouds, tables, annotated sound waves, etc.;
- making movies with After Effects and iMovie to showcase arguments about how captions work; and
- leveraging emergent terms and theories in caption studies such as cultural literacy.
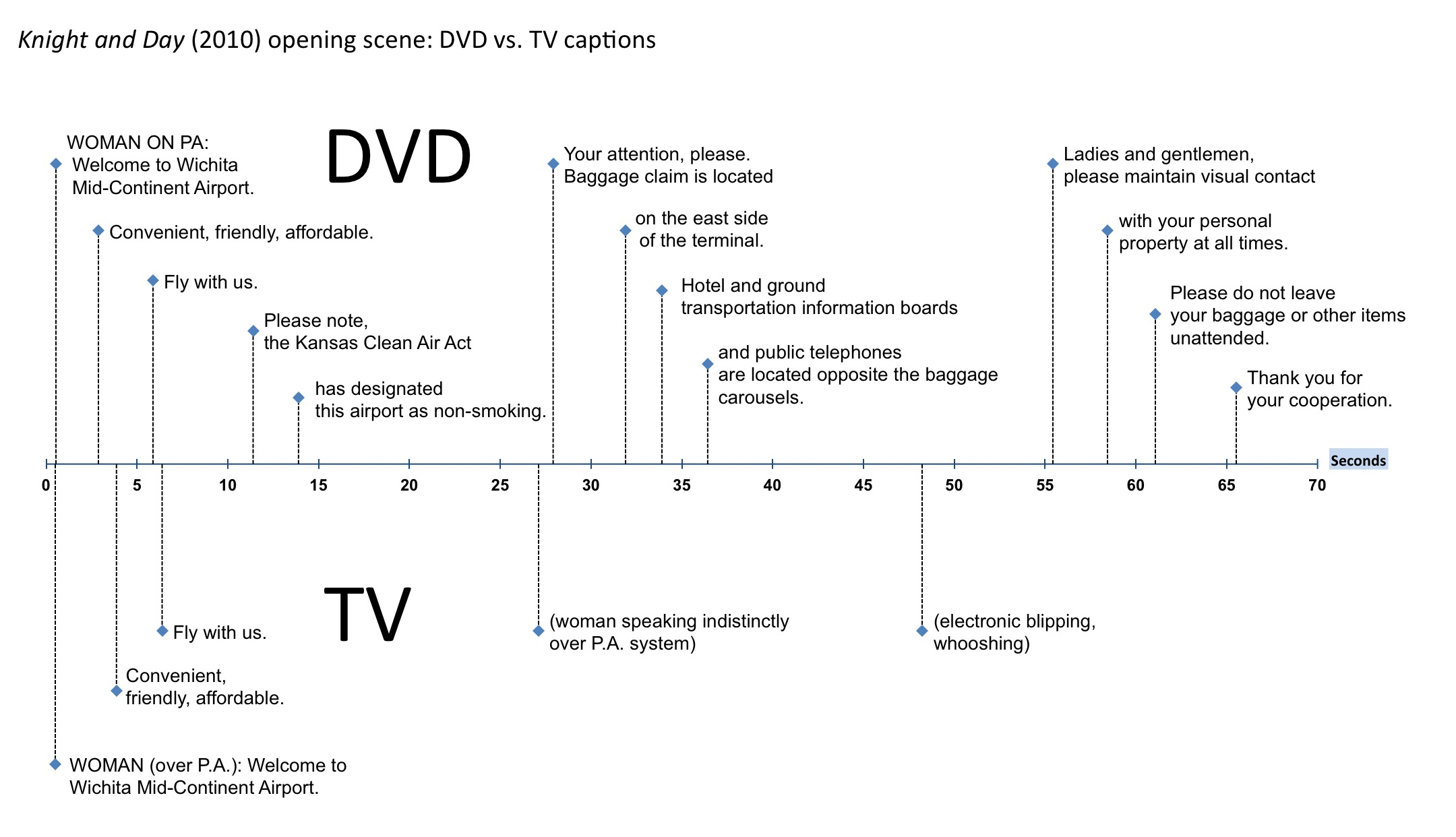
In future versions of this graduate course in web accessibility and disability studies, I plan to assign Reading Sounds. It isn’t exactly a book on doing captioning research (nor was it intended to be). But I think it can lead us there. Consider this figure comparing the DVD captions with the TV captions in the opening scene of Knight and Day (Mangold, 2010). The figure raises questions about tools and methods for collecting data, analyzing it, and visualizing it.
The tools and methods of analysis provide the backdrop to the book's analysis and can be made explicit in a classroom context as students discuss their own research questions and ways of answering them, and presenting their research to a range of audiences.
[gz] As a captioning researcher, what is the biggest problem you face? How have you overcome it?
[SZ] Access is the biggest issue for humanities scholars and others who are interested in studying professional captioning in professional contexts. How do we scale up from the single caption—no matter how rich and full of meaning—to a full-scale analysis at the level of an entire program, multiple episodes, or feature-length movies? Sharing a single example can get people talking and thinking on Twitter, but a sustained analysis requires access to complete files that can be easily studied by the researcher because they are plain text.
There are no public databases of closed captioning files. The files themselves are copyrighted and, in the case of DVDs, locked away inside discs. In the case of television shows, we can transfer recordings to a computer, but we can't extract burned-in-DVR captions to a plain text format such as SRT. (I use the Hauppauge HD PVR to transfer files from DVR to PC.)
By contrast, when a rhetorical scholar sets out to study public rhetoric, access to artifacts does not usually require a number of complicated steps or special software tools. Full text transcripts and high quality videos of political speeches are easy enough to locate (although they may not be fully accessible to all users). But caption files are not released to the public for television shows and movies. Captions need to be extracted and the learning curve for researchers can be steep (assuming the full captions can be extracted at all).
Related to the extraction problem: Multiple caption files will exist for any program that has been subject to redistribution. The concept of a master text does not apply in professional captioning. There is not one official caption file even if one set of captions for a program can be said to have come first. The DVD captions are not more official than the TV captions for the same program. But more importantly, the TV captions aren't necessarily related to the DVD captions because captioners don't routinely consult the work of their predecessors, especially if the preceding captions were produced by a different captioning firm. Netflix and Hulu streaming captions may be the same as the DVD captions, but not always. TV and DVD captions almost always differ in significant ways.
These problems come together in the case of the Hypnotoad captions, which are the subject of Chapter 3 in Reading Sounds. While the Futurama Wiki and other Internet sources identify most of the episodes where the Hypnotoad appears, the captioned video clips themselves were not available online for download. DVD versions were easy enough to find. But because the TV and DVD captions for the same episodes are usually different, I couldn't simply watch DVD versions of the episodes if I wanted to be comprehensive in my analysis. I needed multiple recordings for the same scene: DVD, TV, and Netflix streaming. TV shows/captions aren't available on demand, so I set my television's DVR to record every episode of Futurama. Comedy Central routinely repeats old episodes of this animated program daily, so I waited for the episodes on my list to be broadcast, and then made sure my DVR didn't delete them when it filled up. It probably took a few months for the broadcaster to cycle through the episodes I needed. I also watched the show regularly and discovered that the Hypnotoad made appearances in episodes that the online sources didn't include in their lists. In short, tracking a recurring sound across episodes in a television show, which I describe as a method of doing caption studies, requires persistence and perseverance.
These are the biggest problems I face because I'm primarily interested in captions as rhetorical texts. Extracting those texts (in the case of DVD movies) and locating them in the first place (in the case of recurring sounds across multiple episodes) remain ongoing challenges. Other captioning researchers will have different answers to this question.