Section (1b): Geography & Ownership: Traceroute
Contrary to popular belief the Internet has streets, avenues, and roads similar – in a sense – to any mega-metropolis. While this information has in the past been considered useless to know outside of the technical arena there are now numerous reasons for the general public to learn how utilities like traceroute work. Specifically it’s as important to know where a computer is located as it is to know where a document came from. Censorship in many nations has had the effect that some websites are hosted in alternate countries. While a .com, .net, .org, are often assumed to be located within the United States by their end prefix, this may not be the case. Furthermore when we cite the city of a print publisher in a MLA citation, we’re saying that knowing a print documents origin is important. This section will begin to help you to locate the geographic origin of online documents. You (students) will be using a tool known as traceroute to retrieve this information. Traceroute allows you to approximate the physical location of a website on the Internet and the world.
Each ‘hop’ is basically a street sign that’s directing your data down the windy network roads to the street address of your final destination: the website you’ve requested. When we look at the number of ‘hops’ we are looking at how far away the website is in terms of street signs. In practice there are several truths that transport quite well from the road systems we know in the material world: the more roads one has to travel in order to reach an end destination does not necessarily have any bearing on the overall distance in miles one is required to travel. I could travel on one road for a hundred miles or four roads for two miles. But most of the time the closer the website is geographically located to you, the less ‘hops’ there should be between you and the website. This is not a hard rule and is not one that has any serious impact on network design, but its something to consider when looking at the output of the ‘traceroute’ utility. The final two to three hops (the last two to three hops listed by traceroute) allow you to approximate where the website is located both on the Internet and in the physical world.
Step one: tracerouting http://www.cnn.com
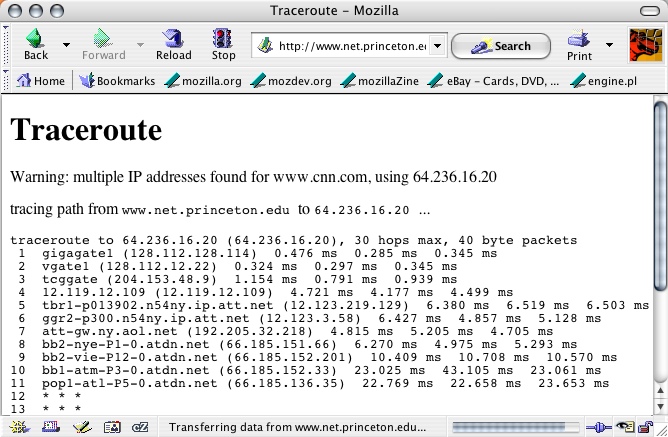
As we can see, from http://www.net.princeton.edu/traceroute.html
(the geography of the traceroute originates in New Jersey) to http://www.cnn.com there are at least 12
‘hops’ numbered in ascending order. We can see that from hop number 12
cnn.com is purchasing or affiliated with the provider atdn.net. If we
wanted to find out more information about atdn.net or find out how
much This ability to
map the location of documents on networks allows you to potentially see
the geography of where documents originate and circulate.
Step two: using traceroute:
To use traceroute, go to http://www.net.princeton.edu/traceroute.html and enter the full website address you wish to trace into the text box provided. After you have entered in the website address with the ‘www’ prefix, hit return on your keyboard.
Copy and paste the traceroute information to your
worksheet in the section provided. Now that you have retrieved your
traceroute information, answer the following questions about your
website here:
Worksheet area:
(1) How many ‘hops’ away is your
website? Twelve hops.
(2) Who is the provider of service for your website?
Where are they located? The service provider (ISP) for my website
is AOL Transit Data Center. Their backbone is located in the US and
Europe.
(3) Is the website hosted outside of its country
of origin? If so, why? No, the website is a US website and it is
hosted inside the legal boundaries of the United States.
Summarizing the importance of traceroute
In the first exercise we learned how to use WHOIS to locate the name, address, telephone number and hosting information of a domain name. With traceroute we are now able to approximate the physical location of the server hosting the website as well as the identity of the ISP that administrates the network hosting the server. Together, these two utilities allow us to begin to contextualize the website based on its geographic origins, “publisher” (ISP), time new authorial information. By using these two utilities we are able to discover important information about the domain the website exists on outside the website proper. Next we will move beyond domain names to look at t even more specific information: the numerical addresses domain names resolve, commonly known as Internet Protocol (IP) addressees.