
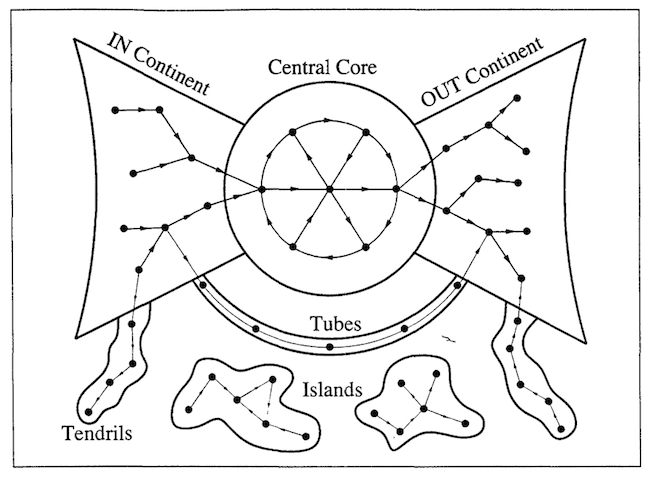
Figure 1: “The Continents of a Directed Network” (Barabasi, 2002, p. 166)
Because of the Internet’s structure, it is not possible for search engines to index all of the Web; that is, to have a record of every page on every site accessible via the hypertext transfer protocol (i.e., http). Although automated programs like spiders can easily crawl the web and index the pages they encounter, the structure of the Internet makes it impossible for them to index all of the Web’s content. One reason for this is that the Internet is a directed network; that is, if there is a link from page A to page B, it is possible for a user to navigate from A to B, but the link will not take the user from B to A. This structure has particular effects on the ability of spiders to navigate the network.
In a network that allows for bi-directional connections, all pages are navigable from any other pages as long as links exist between them. However, the directed nature of links on the Internet has resulted in it being divided into distinct groups of connected nodes (Fig. 1). Albert-László Barabási (2002) identified four such groups, called “continents,” on the Internet: the central core, the IN continent, the OUT continent, and the tendrils and islands (pp. 167–168). The central core consists of most major websites, and a page on this continent is able to connect with any other page. The IN continent is connected to the core, but due to the directed nature of web links it is not possible to navigate from the core back to this collection of nodes. Conversely, even though pages in the core are connected to the OUT continent, it is not possible to return to the core from it. Finally, the tendrils are a series of smaller groups of interconnected nodes that are not connected to any other continents. Additionally, much of the information online is generated dynamically by ”HTML forms, web service interfaces, or… web APIs” (Lu, 2010, p. 866) making them inaccessible to traditional indexing. For these reasons, search engines can only reliably index roughly 24% of web pages, leaving the rest “unreachable by surfing” (Barabási, 2002, p. 165) and, consequently, unreachable by indexing methods that emulate surfing behaviors.
In short, the network that is searched by PageRank and the related algorithms that power Google’s search products is a proprietary index of the Web maintained by the search company that is separate from, and represents only a portion of, the entire Web. Just as the yellow pages that indicate business listings in a phone book are not the businesses they represent, and the order and prominence given to listings in the Yellow Pages affects how readers perceive and access those businesses, search engine databases are not the websites they track and their organization of information is unique to them. This index is the de facto network that most individuals interact with, and the programming and switching behaviors within this network are heavily influenced by PageRank.
Note: Portions of this text are adapted from Jones (2012).