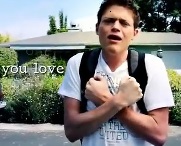
Introduction
Sign language is a visual-spatial modality in which meaning is expressed three-dimensionally through the synthesis of manual, physical, and facial expressions. Signs create meaning through specific hand shapes and configurations, movements, and locations within the semantic space created by the individual. For example, the American Sign Language (ASL) sign for love is two arms moving together and crossed over the heart, as expressed in the image on the upper-left corner of this screen. The hands are both closed in a shared shape, the arms move together and embrace the location of the heart. The sign becomes a kinesthetic embodiment of the abstract concept of love.
Deaf individuals such as me use sign language and physical movement to embody the multimodal sensation of experiencing sound and music. I sway my body as I absorb the vibrations I feel through the air and visualize the beat. This embodied experience is intensified in ASL music videos—multimodal compositions that are explicitly designed to make aural meaning visually accessible across multiple modes.
In ASL music videos, Deaf composers extend the multisensory experience of sound into dynamic visual text that moves on the screen in tandem with their bodies and the beat of the music. The video clip below comes from Sean Berdy’s (2012) ASL music video, “Enrique Iglesias’s Hero in American Sign Language [Sean Berdy],” in which vocal lyrics, dynamic visual text, and signs flow through the screen in harmony. The emotional content is presented through the synchronicity of multiple modes.
The synchronicity of modes—with sound accompanying visual, gestural, and spatial movement—reinforces the value of designing access to various modes in multimodal compositions. In this webtext, I present ASL music videos as examples of multimodal compositions that improve accessibility for more—although not all—users through synchronizing multiple modes. While more inclusive than traditional music videos, ASL music videos still exclude some audience members, primarily those who cannot see the sign language, performing bodies, and dynamic visual text. They are not accessible for everyone—but they show that we can design multiple modes to engage different senses and increase the chances that others can access our meaning.
I use this webtext to demonstrate how ASL music videos can enhance accessible multimodal pedagogies because of the ways that their designers use multimodal strategies to make their compositions more inclusive. I call on instructors and students to analyze ASL music videos and design more accessible multimodal compositions that reach different bodies.
I connect multimodality and accessibility to reflect the potential for communicating through multiple modes to engage more senses. When we express meaning in more than one mode—when we go beyond the spoken word in isolation, for instance—we increase the number of ways that others might access our message. To increase the potential for making multimodal compositions inclusive, we need to synchronize modes so that different bodies and senses can access meaning. I not only support Stephanie Kerschbaum’s (2013) criticism of multimodal texts in which one or more of the modes are rendered inaccessible for some users, such as uncaptioned videos, but also her argument that we need to deliberately design compositions that convey meaning across multiple modes.
I argue that ASL music videos show how synchronizing multiple modes—visual, digital, gestural, spatial, aural, linguistic—strengthens the aesthetic and rhetorical message of a composition and increases the chances of meaning being accessed through different modes. Although we might not be able to make any composition fully inclusive, studying these videos can help composition scholars and students design multiple ways to reach our audiences.
How can we make our multimodal pedagogies and compositions more accessible? Let’s begin by analyzing ASL music videos.