Coming to Terms:
Critical Approaches to Ubiquitous Digital Surveillance
Colleen A. Reilly
"We will create a civilization of the Mind in Cyberspace. May it be more humane and fair than the world your governments have made before."—John Perry Barlow, 1996
The mid-1990s were exuberant years in cyberspace for those who had access, but according to the data from the Pew Research Center (Fox & Rainie, 2014) only 14% of Americans had Internet access in 1995 and 42% reported that they had never heard of the Internet. Nevertheless, Sherry Turkle (1997) posited a new life on the screen, and John Perry Barlow (1996) issued his declaration of independence for cyberspace. A number of culturally relevant sites came online in the mid-1990s, including the Internet Archive (1996) and Slate (1996). In 1995, just prior to the inaugural issue of Kairos, other significant peer-reviewed journals related to writing and communication began publishing scholarship, including CWRL: The Electronic Journal for Computer Writing, Rhetoric and Literature and the Journal of Computer-Mediated Communication.
More significantly for my discussion was the development and refinement of search engines. Google.com was registered in 1997 and incorporated in 1998; prior to that, users had access to AltaVista, Excite, Lycos, and Infoseek. Users learned that search engines were not equal in terms of their efficacy. However, I do not think that most users envisioned the degree to which the tools used to locate information and conduct research online would evolve into the primary players in the collection of data about their users: Today the searchers have become the subjects of search and sources of data that are invisibly circulated, traded, and monetized online. The ubiquitous surveillance of users by corporations, including search engines, and the impossibility of opting out if individuals want to continue to take part in communication, commerce, or other activities online makes it imperative to develop new digital literacies. As Cynthia Selfe (1999) argued at the turn of the century, developing such literacies requires active interventions (p. 11). Below I highlight some freely available digital tools that allow users to "track the trackers" (see Kovacs, 2012; Mayer, 2011) in order to collect and repurpose the data generated through online activities in service of small data research, and simultaneously increase digital literacies by making the invisible mechanisms of online surveillance visible.
The deceptive transparency of search
Online search has always seemed deceptively transparent in the most basic way meant by Jay David Bolter and Richard Grusin (1999): Typing a term or phrase into the search box appears to provide seamless access to online content, with no mediation necessary. With the mechanisms of search elided, most users have been content to equate the results with the answers and have not been motivated to delve into the technological processes producing those results. Interestingly, as the screen shot below demonstrates, from the start, search engines have been connected with and derived revenue from advertising; however, initially these connections were quite overt.
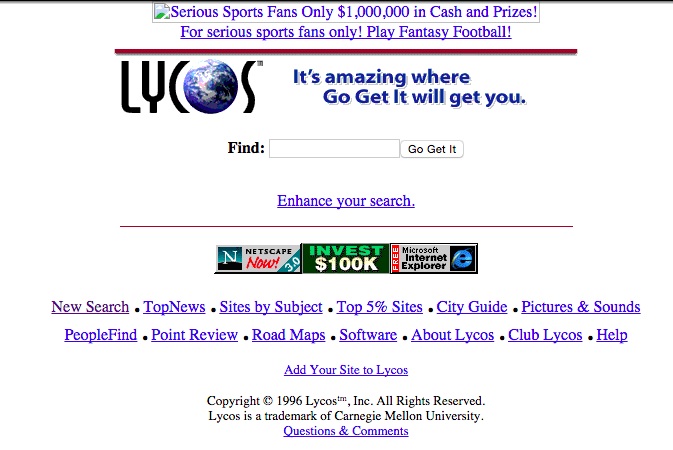
In the mid 1990s, in order to develop a critical view of search while practicing data-driven argumentation, I used a typical assignment in my introductory technical writing courses that asked students to search for a list of terms using five different search engines and compare the results in an evaluative report. This sort of assignment was especially relevant in this early period of search; the best practices for crawling and delivering results to users were not codified and results could vary widely. The variance, however, was determined by the mechanisms of crawling, indexing, and delivering results and not, as today, by the search engine's construction of the user.
Google came to dominate search because it was effective and, by 1999, its interface stood out as simple and clean in comparison to the cluttered interfaces of its competitors, who had shifted to branding themselves as portals, as the screen shots below illustrate.
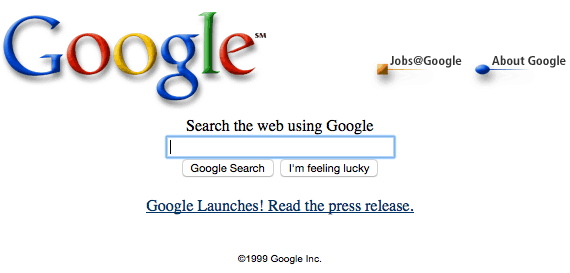
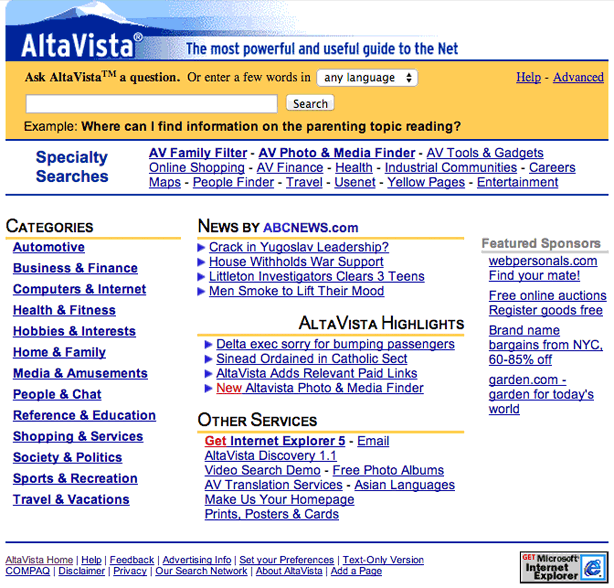
Google promoted the transparency of its search mechanism and the democratic nature of its results determined entirely by Google's PageRank technology: "Google's complex, automated search methods preclude human interference. Unlike other search engines, Google is structured so no one can purchase a higher PageRank or commercially alter results. A Google search is an honest and objective way to find high-quality websites, easily" (Google, 1999). Google's emphasis on removing human interference tellingly omits mention of technological interference, and, by 2005, Google began to personalize results for users who were signed into Google while searching, allowing them to decide to connect their search history with future search results. However, in 2009, Google moved from an opt-in model to the model prevalent today of surveilling users by default. In 2012, Google began to further personalize results using additional user data including information from Gmail and Google+ as well as users' geographical locations, search histories, personal sharing, and online social connections. While this form of surveillance can certainly aid users to garner results targeted to their needs, the new degree of personalization could result in users receiving the results that Google believes they want based on their user profile, which could have significant ramifications on research, communication, and democratic discourse in that users may be less likely to encounter contrary points of view.
Because most users are unaware of the personalization of results and the online activities that trigger personalization, increasing literacy related to search surveillance requires making the effects visible—a seemingly daunting task akin to proving the negative. In order to grasp the ramifications of search relativization based on surveillance and personalization, users should experience it firsthand, which is difficult to do independently. In a fascinating study, Martin Feuz, Matthew Fuller, and Felix Stalder (2011) successfully produced personalized Google results for designated user profiles thereby demonstrating the degree to which personalization can be specifically directed. While other search engines track users, Google's dominance makes it the focus of most search engine research today. Through submitting automated search queries, Feuz, Fuller, and Stalder trained Google to recognize user profiles for three philosophers: Immanuel Kant, Friedrich Nietzsche, and Michel Foucault. This was accomplished through submitting approximately 6,000 search queries derived from the indices of seven of each philosopher's books. Through automation, Feuz, Fuller, and Stalder (2011) submitted over 18,000 search queries and examined 195,812 results. By analyzing this large corpus of data, they determined that the philosophers' user profiles received personalized search results when compared with those of an anonymous user. Additionally, they discovered that personalization begins quite quickly, decreases the variety of results, and occurs even when the philosopher's user profile searches for keywords unrelated to the crafted user identity.
In Spring 2013, I worked with my students in my professional writing senior seminar to demonstrate that a small data project can also produce evidence of search personalization, increasing students' literacies related to search. Students worked in groups to create user profiles connected to particular ideologies, political perspectives, and interests; they accomplished this through manually submitting only 50 to 100 total search terms. Their work was informed by Danny Sullivan's (2012) illustrative piece detailing the range of triggers for personalization. To conduct such research, students had to learn to create a research browser, cleansed of any search history, geographical markers, and other identifying information; through this process, they learned how difficult it is to search anonymously.
The Digital Methods Initiative (DMI) provides clear instructions on setting up a research browser. Like Feuz, Fuller, and Stalder (2011), students discovered that their specific users, such as green energy supporters or global warming skeptics, received results that differed from anonymous users when searching for unrelated terms such as books, films, or cars. Significantly, one group also learned that consistently adding modifiers to search terms, including the best or top 10, would result in later searches returning similarly modified results even when the modifiers were not used in the subsequent search strings. For example, if a user profile was developed using the worst as part of every search string, a subsequent search for places to live would include lists of the worst in the top 10 results. As this reflects, through structured, small-scale projects, the invisible effects of search personalization can be made visible by students; such work can help them to approach search critically, give them the tools to decrease personalization if desired, and prompt them to seek alternate tools for search that do not track users, including search engines like DuckDuckGo , ixquick, and startpage.
No one surfs alone
Brian Kennish (2011), the inventor of Disconnect, highlighted at his presentation at Def Con 19 that Google's tracking technologies are used to collect users' data from a great number of digital spaces. Almost no site is free from cookies, beacons, or analytics trackers, as demonstrated by Ghostery, the browser extension that reveals to users the types of trackers surveilling them on each site they visit. My university's site, like most, tracks users with Google Analytics; using Ghostery's blocking feature to prevent tracking disables my ability to obtain search results from my university's site, highlighting that when working in digital spaces, opting out of surveillance can make functioning impossible. I have experienced similar difficulties in successfully shopping online while Ghostery's blocking feature was enabled.
Estee Beck (2015) provides here a wonderful overview of the history and functionality of digital tracking technologies and outlined a useful heuristic for educators that aids students to make visible their digital identities. As Beck indicated, Ghostery, AboutAds, and other tools can be harnessed for projects that we can construct with our students to make visible the tracking technologies moving along with them from site to site as they research, communicate, and shop. For example, Ghostery identifies and categorizes each tracker and provides a profile (shown below) that could be useful for students' research; students can profile the trackers, determine which genres of sites contain the greatest numbers of trackers, and critically examine their privacy policies.

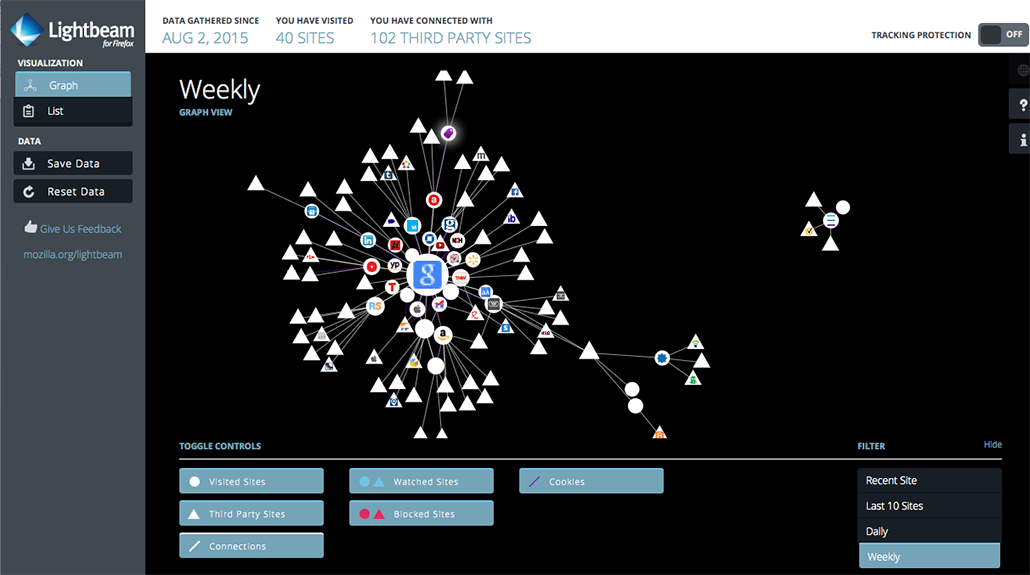
The DMI developed a tool that partners with Ghostery, allowing researchers to repurpose Ghostery's tracking information for their own complex research projects. Instead of simply viewing each tracker's profile separately or examining the list of trackers on each site, through the DMI's Tracker Tracker, users can submit up to 100 URLs and output a matrix of all of the trackers present, making it possible to survey a corpus of sites and interrogate the extant tracking technologies and their interconnections. The Tracker Tracker tool and its associated methodologies exemplify DMI Founder Richard Rogers' (2010) push to develop natively digital research practices and associated tools (see also Rogers, 2013). Carolin Gerlitz and Anne Helmond (2013) illustrated the power of the Tracker Tracker to reveal the penetration of Facebook tracking across a wide range of websites, making visible “an alternative network of connections, one that is not established through mutual linking practices between websites, but based on associated trackers” (pp. 1356–1357). Visualizing the Tracker Tracker's results in Gephi provides a generative network representation, although Gephi's learning curve may be steep for some users. Another browser extension, Lightbeam for Firefox, records the sites that users visit, identifies the third-party data collectors linked to those sites, and provides a graphic representation of those connections, as the screenshot below reveals. Tools like Lightbeam can facilitate research into the interconnections between sites and their trackers, revealing links that Ghostery misses in some cases. For instance, Lightbeam showed me that in addition to Google Analytics, Vimeo was collecting my data from my university's site; interestingly, my institution does not reveal that connection to users. To comply with European Union (EU) regulations (Solon, 2012), the University of Edinburgh (2015), for example, provides detailed information about all third-party data collectors, including Vimeo, revealing that Vimeo's cookies may remain with users from two weeks to 10 years.
The tracking and the resulting personalization in electronic spaces is spreading despite users' discomfort with this practice (Purcell, Brenner, & Rainie, 2012; Turow, King, Hoofnagle, Bleakley, & Hennessy, 2009). Increasing users' digital literacies regarding tracking is possible through the use of the sorts of free tools discussed above. Building on this awareness, users can be motivated to demand that the organizations with whom they interact online move beyond the failed regime of notice and choice to one that enhances trust and bolsters the organization's reputation by making tracking practices transparent and allowing users to easily opt out (Martin, 2013). While it may seem impossible, and even undesirable, to stop digital surveillance completely, increased literacy can also empower users to advocate for more transparency to their elected representatives and to the Federal Trade Commission to create and enforce meaningful Do Not Track laws (Fomenkova, 2012; Mohamed, 2012). Using small data research projects and the associated tools discussed above, researchers, instructors, students, and activists can also shift from awareness to action and capture the data produced to conduct their own research projects while becoming more critical users of digital spaces and decreasing the imbalance of power between the trackers and the tracked in digital environments.
References
Barlow, John Perry. (1996, February 8). A declaration of the independence of cyberspace. Retrieved from https://projects.eff.org/~barlow/Declaration-Final.html
Beck, Estee N. (2015). The invisible digital identity: Assemblages in digital networks. Computers and Composition, 35, 125–140.
Bolter, Jay David, & Grusin, Richard. (1999). Remediation: Understanding new media. Cambridge, MA: MIT Press.
Fomenkova, Galina I. (2012). For your eyes only? A “Do Not Track” proposal. Information & Communications Technology Law, 21(1), 33–52.
Fox, Susannah, & Rainie, Lee. (2014, February). The Web at 25 in the US. The Pew Research Center. Retrieved from http://www.pewinternet.org/2014/02/25/the-web-at-25-in-the-u-s/
Feuz, Martin, Fuller, Matthew, & Stalder, Felix. (2011). Personal Web searching in the age of semantic capitalism: Diagnosing the mechanisms of personalisation. First Monday, 16(2). Retrieved from http://firstmonday.org/ojs/index.php/fm/article/view/3344/2766
Gerlitz, Carolin, & Helmond, Anne. (2013). The like economy: Social buttons and the data-intensive web. New Media & Society, 15(8), 1348–1365.
Google.com. (1999, October). Why use Google? Internet Archive. Retrieved from https://web.archive.org/web/19991012035335/http://google.com/why_use.html
Kennish, Brian. (2011). Tracking the trackers: How our browsing history is leaking into the cloud [Video file]. Def Con. Retrieved from https://www.defcon.org/html/links/dc-archives/dc-19-archive.html#Kennish
Kovacs, Gary. (2012, February). Tracking our online trackers [Video file]. TED. Retrieved from http://www.ted.com/talks/gary_kovacs_tracking_the_trackers
Martin, Kirsten. (2013, December). Transaction costs, privacy, and trust: The laudable goals and ultimate failure of notice and choice to respect privacy online. First Monday, 18(12). Retrieved from http://journals.uic.edu/ojs/index.php/fm/article/view/4838/3802
Mayer, Jonathan. (2011, July 12). Tracking the trackers: Early results. CIS: Center for Internet and Society. Retrieved from http://cyberlaw.stanford.edu/blog/2011/07/tracking-trackers-early-results
Mohamed, Nada. (2012). The Do Not Track Me online laws: Creating a ceiling when the sky's the limit and we are halfway to heaven. Information & Communications Technology Law, 21(2), 147–154.
Purcell, Kristen, Brenner, Joanna, & Rainie, Lee. (2012, March 9). Search engine use 2012. The Pew Research Center. Retrieved from http://www.pewinternet.org/2012/03/09/search-engine-use-2012/
Rogers, Richard. (2013). Digital Methods. Cambridge, MA: MIT Press.
Rogers, Richard. (2010). Internet research: The question of method: a keynote address from the YouTube and the 2008 Election Cycle in the United States Conference. Journal of Information Technology & Politics, 7, 241–260.
Selfe, Cynthia L. (1999). Technology and literacy in the twenty-first century: The importance of paying attention. Carbondale: Southern Illinois University Press.
Solon, Olivia. (2012, May 25). A simple guide to cookies and how to comply with EU cookie law. Wired.Co.UK. Retrieved from http://www.ed.ac.uk/about/website/privacy/third-party-cookies
Sullivan, Danny. (2012, November 9). Of "magic keywords" & flavors of personalized search at Google. Search Engine Land. Retrieved from http://searchengineland.com/flavors-of-google-personalized-search-139286
Turow, Joseph, King, Jennifer, Hoofnagle, Chris Jay, Bleakley, Amy, Hennessy, Michael. (2009). Americans reject tailored advertising and three activities that enable it. Social Science Research Network. Retrieved from http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1478214
University of Edinburgh. (2015, July 22). About our website: Third-party cookies. Retrieved from http://www.ed.ac.uk/about/website/privacy/third-party-cookies