CONTRIBUTORS
José Manuel Flores
Dr. Lucía Durá
AFFILIATIONS
The University of Texas
at El Paso
EMAILS:
4
Dimensions of Sound: A Conceptual Framework
While sound is one medium in multimedia and one mode in multimodal research and pedagogy, it remains under-explored and under-used. Heidi McKee (2006) offered us an early examination of sound, drawing attention from approaches in voice, music, theater, and film studies to examine four elements: vocal delivery, music, special effects, and silence. Similar to Greg Goodale (2011), she also explained that “rhetoric and composition scholars have discussed the visual a great deal, but we haven’t as of yet turned our attention to sound” (McKee, 2006, p. 336). McKee exposed interesting ideas about the value of voice instead of the discourses created by the pen. Although Aristotle explained the treatment of voice in On Rhetoric, the volume of sound, modulation of pitch, and rhythm are the three things that a speaker bears in mind (Aristotle, 2007; Freeman & Auster, 2011). Closer to our times, McKee (2006) cited Thomas Sheridan, who called for an increased emphasis on the nonverbal aspects of vocal delivery, such as the “essential articles of tone, accent [and] emphasis” (p. 340). Subsequently, McKee (2006) also explained how Theo Van Leeuwen “broke voice down even further into several qualities that carry culturally formed communicative meanings” (p. 340).
On the other hand, some approaches like Peter Elbow’s (2012) vernacular eloquence emphasize oral culture, contributing to our understanding of literacy as orality (Hoermann & Enos, 2014). However, Elbow’s (2012) focus was not precisely on sounds, and at some point, he even reduced the concept by stating that “sounds are nothing but air molecules that are squeezed closer together than usual, spoken words decay the moment they are heard” (p. 14). Even though orality and discourses are certainly part of our focus, soundscapes in general and this project specifically encompass all sounds, paying attention to their rawness and in some cases also to the ways they are layered and manipulated in others. This work has a similar focus to Steph Ceraso’s (2018) proposal of multimodal listening pedagogy because sound is, in fact, a full-bodied act, more than an ear-centric act. Briefly, Ceraso proposed that when we listen, not only our ears perceive that sensation, but also other parts of our body, producing a full-body act experience. Although we agree with this idea, a focus on the ear-centric act is a beginning and requires exploration and inquiry for our study: what I’m listening to? And how I’m listening? How is this sound a full-bodied act? That is to say, to start with what R. Murray Schafer (1977) called an ear cleaning, “a systematic program for training the ears to listen more discriminatingly to sounds, particularly those of the environment” (p. 272). “Dimensions of sound” contributes to this emerging pedagogy as a framework for scholars and students in rhetoric and writing studies.
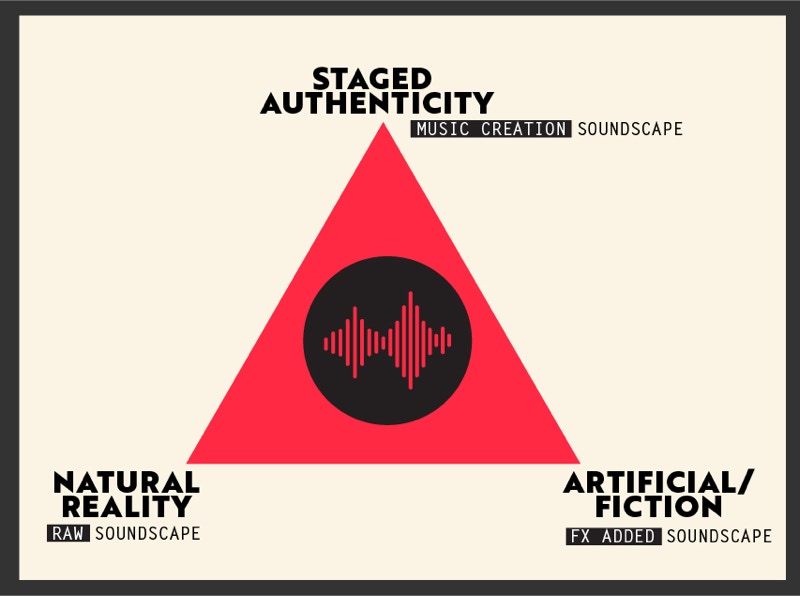
Dimensions of sound is a conceptual framework that facilitates starting points for identifying sub-genres of soundscapes, not only for the analysis but also for the sound design of soundscapes. At its essence, the model requires three steps: (1) ethnographic observation and sound collection, whereby the researcher-subject listens for interesting patterns, discrepancies, and moments within a cultural, historical, artistic, and/or environmental context; (2) a deep appreciation of sounds, which allows us to understand their nature and to recognize any processes of technological manipulation to which sounds are exposed for their creation and manipulation—in other words, deconstructing and mapping sounds based on the three sub-genres of Natural Reality, Staged Authenticity, and Artificial Fiction (see Figure 5 below and Flores, 2019); and (3) interpretive analysis of the epistemological, ontological, and axiological elements of a soundscape. Dimensions of sound does not intend to be a universal analysis model but a way to establish starting points to listen to the sound and organize it through soundscape sub-genres.
From an aesthetic perspective, when one listens to an acoustic ecology, it is something amazing. Still, when one listens with total attention, it becomes seductive; there are so many details we don’t notice in the sounds around us until we listen deeply, or in our case with the intentionality that a conceptual framework provides. By listening with purpose and consistently, the auditory sense is sharpened and enriched, but so is the imagination. It can be argued that this deep, intentional listening produces a rhetorical effect, which can influence written and oral compositions. In this sense, writing and sound are not so far apart. To better understand the influence of sound on our lives, it helps to carry out the ethnographic process through field recordings to investigate the border identity which interests us.
For our sample, we delimited the geographical areas of greatest flow and interaction between both cities, such as the central areas of Juárez and El Paso, international bridges, and areas near the border crossing. To collect the sounds, we used specialized audio equipment, known as a Handy Recorder. There are many brands, models, and prices. This type of technology offers us great versatility and quality since we have the option to plug into it a wide variety of microphones and accessories, depending on the type of sound we intend to capture. In the absence of a Handy Recorder, a cell phone or tablet will suffice. There are many free and paid applications available and some basic techniques that can help novice and expert sound researchers obtain favorable results. Similarly, some low-cost accessories such as hands-free headphones and/or a selfie stick can be integrated, which serves to capture a specific sound at a certain distance. To capture the sounds for this project, we used a Handy Recorder Zoom H4n and six types of microphones for different purposes, as well as some soundscapes made with the iPhone Voice Memos app, listen to the example (Audio 7).
Audio 7. “Singer at El Paso del Norte port of entry.” Source: Border Soundscapes Project (2019)
Once we were situated in a specific place, we listened to the environment without using headphones and identified sounds that caught our attention. We proceeded to listen with headphones, capturing the sound with a specific microphone. As a methodological process, we record the essential information about the acoustic ecology through a logbook for field recordings (Figure 4) created on DataScope, a digital platform to collect data from a mobile device using a customized form.
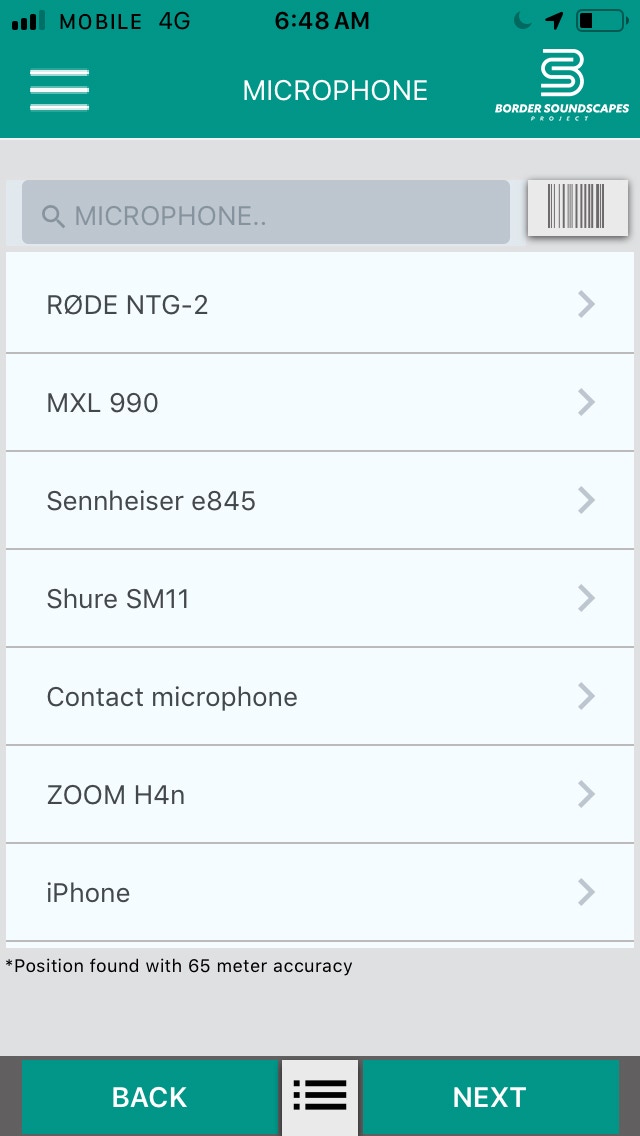

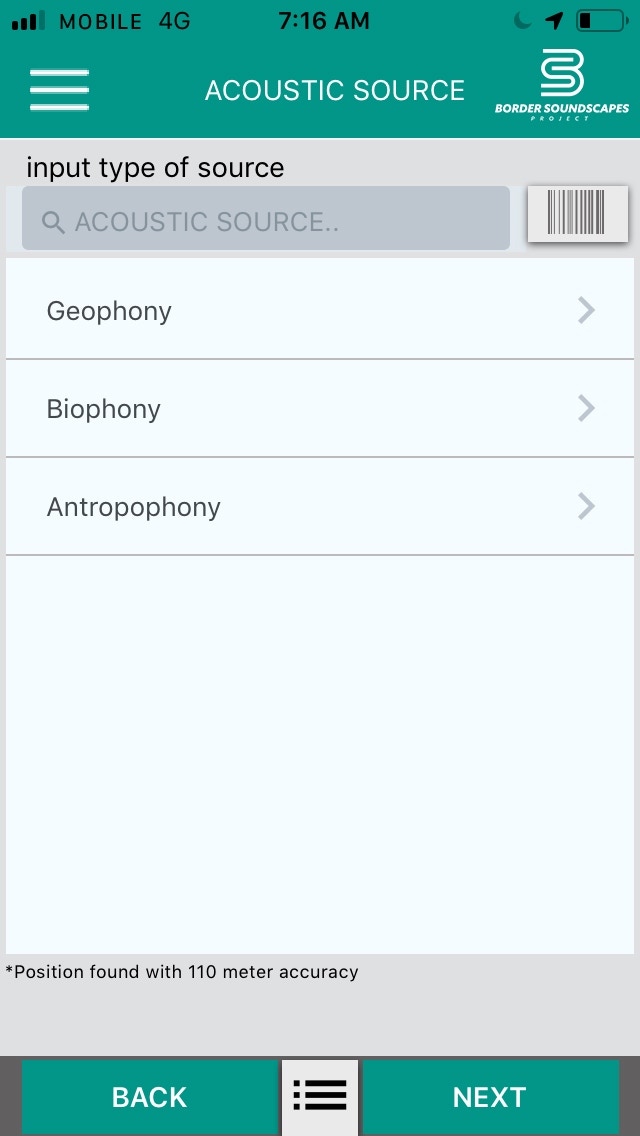
Figure. 4 “Logbook for field recordings”
In the logbook, we entered data such as file name, GPS location, date, time, duration, information related to the Handy Recorder settings, atmospheric conditions, and observations while gathering the sounds. We determined the acoustic source, including field notes, to analyze the sounds and the audio files’ metadata management. Some recordings were short and others long, depending on the context of the acoustic ecology. Brief sounds are usually sounds whose pattern is repetitive, and for a few minutes, the alterations are minimal. On the contrary, long recordings happen when significant changes occur in acoustic ecology that are able to grab our attention for a while. When listening using the Handy Recorder, the microphone, and the headphones, it is possible to perceive details that our ears do not naturally detect since the hardware amplifies the sound. During that process, one can choose to use a specific microphone or moving closer to or further away from the area where sounds influence the field recording.
1. In Audio 8 we experimented with the integrated microphone by default to the Zoom H4n. This original accessory gives us the option to rotate the mic to change the capture angle from 90 to 120 degrees, allowing us to obtain ambisonic sound with high definition stereo quality, ideal for capturing ambient sound indoors and outdoors. However, it is usually sensitive to very intense noises, such as strong winds, horns, motorcycles, and even the equipment’s movement. Its structure produces a distracting cracking noise that can affect field recordings. The audios and explanations that follow offer a sound by sound rationale for the microphones that we used to capture different types of sounds. Our hope here is to offer some methodological advice to those seeking to embark in this kind of research.
Audio 8. “Pedestrian Crosswalk Light I” Source: Border Soundscapes Project (2019)
2. To avoid distracting noises, in Audio 9 we used a Sennheiser e845 super-cardioid dynamic vocal microphone for sounds that require precise detail, reducing ambient noise, not entirely, but drastically. However, this microphone is ideal for recording voice, animal sounds, and capturing objects with greater precision without eliminating ambient sound.
Audio 9. “Pedestrian Crosswalk Light II” Source: Border Soundscapes Project (2019)
3. Later, in Audio 10 we used a Rode NTG2, this ambient microphone detects vibrations in the air with great definition, but in turn, it can focus on the specific place to capture soundscapes (e.g., the sound of birds, the bustle of the city).
Audio 10. “Pedestrian Crosswalk Light III” Source: Border Soundscapes Project (2019)
Audio 11. “Pedestrian Crosswalk Light IV” Source: Border Soundscapes Project (2019)
4. For Audio 12, we used the MXL 990, a specialized condenser microphone for recording studios, radio stations, and podcasts. Although it is not highly recommended for field recordings because it is susceptible to noise, its capture versatility allows us to hear too distant sounds. But in some way, its vulnerability to noise enables a 360 capture of an acoustic ecology.
Audio 12. “Pedestrian Crosswalk Light V” Source: Border Soundscapes Project (2019)
5. A contact microphone was used for Audio 13. A contact microphone is designed to amplify physical bodies’ sounds (e.g., musical instruments such as acoustic guitar, violin, cello, among others). It sticks to an instrument and receives the sound vibrations. For the design of soundscapes, it is an ideal tool for listening to sounds produced inside artifacts such as a clock, the engine of a running car, and traffic lights, among others.
Audio 13. “Pedestrian Crosswalk Light VI” Source: Border Soundscapes Project (2019)
Once we captured the sounds, the first step was to create categories of analysis to manage the audio archives in an organized way. First, we determined the type of source. Outdoor sources include urban sounds in general (wide area) and foreground (narrow area), direct shot (minimum area) of parks, squares, international bridges, suburbs, wildlife, and people. Indoors, the categories are similar but focused on the influence of sounds in concentrated spaces. We recorded all of this information in the field recording logbook to facilitate the subsequent cataloguing and analysis of the audio clips in the software. Next, for more accurate management, we established the three primary acoustic sources conceptualized by Bernie Krause (2015) (geophonies, biophonies, and antropophonies), stated in section 2. We listened to the soundscapes to determine the acoustic source. Finally, in the pursuit to understand border identity, we filtered our experience through Schafer's (1977) postulates, which are essential features of the soundscapes, keynote sounds, signals, and soundmarks. Keynote sounds are those produced by nature or even humans that provide us a reference from an acoustic ecology. “Keynote sounds do not have to be listened to consciously; they are overheard but cannot be overlooked, for keynote sounds become listening habits in spite of themselves [...] the sea is the keynote sound of all maritime civilizations” (Schafer, 1977, p. 9). Signals are those sounds that seek to attract our attention, such as alarms, cellphones, car horns—those that seek to alert us. A soundmark is a sound that people easily recognize from a specific acoustic ecology and provides the full context of the exact place through sound—for example, the “ding ding sound” of Hong Kong’s tramway, iconic for their citizens. Another example is the Big Ben chimes recognized by many people from London and visitors around the world. For Schafer, “the unique soundmark deserves to make history as surely as a Beethoven symphony. Its memory cannot be erased by months or years” (p. 239).
We proceeded to review the collected audios and processed them in the audio production software. In our case, we used Adobe Audition, a software that is part of the Adobe Creative Cloud. Membership is required to use it, but the cost is outweighed by a vast amount of sound analysis, effects, editing, and correction tools. Some universities have access to Adobe Creative Cloud and make it available for students, often on specific campus computers.
Otherwise, there are excellent free alternatives, such as Audacity, which is used to edit, add effects, correct audio clips, and create high-quality mixes. For the analysis of waveforms, you can use Pratt, a free software to analyze phonetic dialogues. There are valuable alternatives in a free mode for scientific soundscapes analysis, such as Raven, a software from The Cornell Lab’s Center for Conservation Bioacoustics that also offers free tutorials in different languages. Other free options require code programming skills, such as Seewave R, Warble R, and Luscinia, the essential tools used for bioacoustics analysis of field recordings. When carrying out an analysis, we can collect data to identify the physical qualities of sound (pitch, duration, intensity, and timbre) and have a clearer understanding of the sound phenomenon.
Figure 5. Dimensions of sound. Source: Flores (2019)
What you get from the field recordings are raw sounds; what in the context of the dimensions of sound framework we call Natural Reality (Figure 5). From the perspective of a naturalist or anthropologist, Natural Reality corresponds to a Soundscape close to the reality of its acoustic ecology, that is, to raw sound, the sound as it was collected, without technological alterations. On the other hand, Artificial Fiction corresponds to when the raw sound is technologically manipulated. This dimension is characterized by alterations to natural sounds, such as volume, speed, the addition of some sound effects (echo, reverb, chorus, equalization, etc.), and even the integration of other soundscapes to create an artificial, fictional landscape. It can be heard as natural, but whoever designed it knows that it is made employing layers of sounds. As for Staged Authenticity, it corresponds to the process in where the sound goes through the first two dimensions to juxtapose musical elements or beats created with natural sounds, but now its result is a sound with artistic functionality. Our end goal in this framework is interpretive. We seek to identify a dialogue between rhetoric and epistemological, ontological, and axiological theories that help us understand the different components of the social dynamics of acoustic ecology, in our case, the Paso del Norte Region. To get to that point, we separated sounds based on the sub-genres of the dimensions of sound framework, beginning with Natural Reality. Audio 14 contains recordings of Natural Reality soundscapes.
Audio 14. Field recordings “Natural Reality.” Source: Border Soundscapes Project (2019)
In the first recording, the characteristic gales of this border area are heard during the spring season, especially between the months of February to April. In the second recording, the noise of both cities is heard. To achieve this, the microphone was placed exactly on the border dividing line, capturing the sound produced by the road from both sides. Physically, the wall divides us but the sounds spread beyond the fences. Finally, in the last recording, the song of some insects is perceived, located on the campus of The University of Texas at El Paso, located directly across the river from Felipe Angeles neighborhood in Ciudad Juárez. At another time, we collect the song of some “Figeater Beetles” or “Mayates” as it is called in Juárez, México. These four elements make up a Natural Reality that emerges from sister cities.
Audio 15. Field recordings “Artificial Fiction.” Source: Border Soundscapes Project (2019)
Audio 15 contains an example of Artificial Fiction. Here, fiction is a simulation of reality and the artificial. Although the sound originates from something natural or raw, we have juxtaposed three layers of sound into an Artificial Fiction through the use of Adobe Audition technology to simulate this dimension of sound. While a Natural Reality recording depicts raw, pure sound, the fact that that sound was selected and edited into a track entails a level of interpretation. Artificial Fiction recordings comprise further authorial decisions and interpretations regarding what makes it into a track and what additional track is layered, and when and how these are combined. Still, a key distinction of this sub-genre is that it gives the illusion of being a raw sound, not mixed.
Audio 16. Field recordings “Staged Authenticity.” Source: Border Soundscapes Project (2019)
Ultimately, in Audio 16, we can hear an example of what we call Staged Authenticity. That is, we take something authentic, natural, or raw and take it to the level of the artistic, the creative, the staged. We hear a simple musical composition in which all the sound elements of the other two dimensions are juxtaposed. A creative process is carried out where we mix in work by sound artists and soundscapes collectors such as Yosi Horikawa, Max LL, PLVCES who turn their field recordings into musical creations. As shown in this section, Dimensions of Sound establishes starting points for studying soundscapes, also proposing itself as a conceptual framework to name the productions that arise within this sound genre. Our aim is to offer a way to distinguish between raw, artificial, and staged soundscapes.
Dimensions of Sound is a resource for scholars and students to establish formal characteristics when talking about soundscapes in rhetoric and writing studies. Dimensions of Sound seeks to complement the soundscape terminology coined by Schafer, such as keynote sounds, soundmarks, and sound signals. At the same time, our approach seeks to contribute to a theory of soundscapes conducive to reliable qualitative research. According to our conceptual framework, through an epistemological base, it is possible to identify the objectivity, the veracity, and universality of sound. Ontologically, we can define the structure of sound and its aesthetic characteristics from a natural, artificial, or artistic notion of sound itself. Axiologically, we can set and identify how the physical qualities of sound influence metaphorically and concretely the values of humans and their identities and communities by inferring what notions, desires to manipulate, and interpretations soundscapes trigger in humans when exposed to them.
The Border Soundscapes Project